flowchart TD
A[rag_agent] --> B[InputGuardRail]
B --> C[guardrail_function]
C --> D[GuardrailFunctionOutput]
D --> E{tripwire_triggered?}
E -- Yes --> F[Throw <br> InputGuardrailTripwireTriggered <br> Exception]
F --> G[Decide Next Course of Action]
E -- No --> A
Part 3 - Exploring OpenAI Agent SDK with Local Models (Ollama)
Agents
LLMs
experiments
Exploring GuardRails!
In this part, I’m going to document what I have learnt about InputGuardRail and OutputGuardRail. Simply put, these are essentially hooks placed before & after the main LLM call, that the agent makes to perform its task.
The purpose of these hooks is to have better control over the LLM input and output and needless to say, the usecase varies. Typical examples are :
- For input guard rail, you might wanna :
- inspect the incoming user input to either filter for harmful or unrelated data, so that the application can either refuse or take mitigation even before the LLM is invoked.
- transform or map user input to different data before sending it to the LLM for inference.
- For output guard rail, same pattern follows, where you might wanna make sure LLM’s response is unbiased or relevant before sending it back to the user.
Guard Rails ?
Guard rails and Hand offs were touted to be some of the USP1 of OpenAI Agent SDK. Even though the class names sound as though something magical is happening, in reality, these are just function callbacks that gets called before and after the agent’s LLM invocation.
Now what you do within those functions are completely usecase specific. For example, you could have a procedural imperative sequence of steps that performs the input / output parsing or it could also be another LLM call, either direct or calling other tools / agents which will invoke a LLM call within that context to perform the tasks. This is also known as LLM As Judge pattern i.e using LLM to critique another LLM’s response2.
There can be different ways in which these hooks or callbacks can be implemented and each Agent SDK chooses their way. When it comes to OpenAI Agents SDK, the way these callbacks are implemented is kinda bloated, in my opinion. You will see what I mean shortly!
Input Guardrails Example
Let’s start with an example of using InputGuardRail. As a remainder, Input Guardrails are generally used to catch the input before it is sent to the Agent’s LLM invocation. Lets go over the code line by line as usual
from agents import (
Agent,
1 InputGuardrail, GuardrailFunctionOutput, InputGuardrailTripwireTriggered,
Runner, function_tool, set_tracing_disabled
)
from agents.extensions.visualization import draw_graph
from pydantic import BaseModel
import asyncio
from util.ollamaProvider import OllamaProviderAsync
2from util.localRAGProvider import LocalRAGProvider
set_tracing_disabled(disabled=True)- 1
-
First let’s start off by importing
InputGuardrail, GuardrailFunctionOutput, InputGuardrailTripwireTriggeredclasses fromagentspackage.InputGuardrailis simply any class that accepts any function that can return aGuardrailFunctionOutputobject. Simply put, during one of those input/output hooks, theAgentclass simply calls back the function wrapped underInputGuardrail, which is expected to return an object of typeGuardrailFunctionOutputwhen called. - 2
- For this example, I’m also performing a RAG as the main agent’s task. Hence I created a utility class that performs RAG using Ollama Embeddings.
Tip
You can click on the number circles like ⓵ to highlight the corresponding line on the code snippet for easy reference!
Before we proceed further, I would like to paint the usecase Figure 1 we are trying to achieve in this example. The main agent named rag_agent is tasked to perform RAG on PydanticAI’s documentation. I simply took a dump of this file and turned it into a knowledge-base located under ./kb/ path, which this rag_agent will use to perform the RAG on, using a function tool named get_answer_about_pydanticai.
But, before the input is passed to the rag_agent, we insert a filter to sample3 the input and do something, anything with it. In this example, we are going to use another agent named input_guardrail_agent to act as LLM as Judge4 to determine whether the input query is relevant to the PydanticAI topic. If so, the output of guard rail agent will be used to respond to the user. If not, the control flow will be routed back to the rag agent to perform its task.
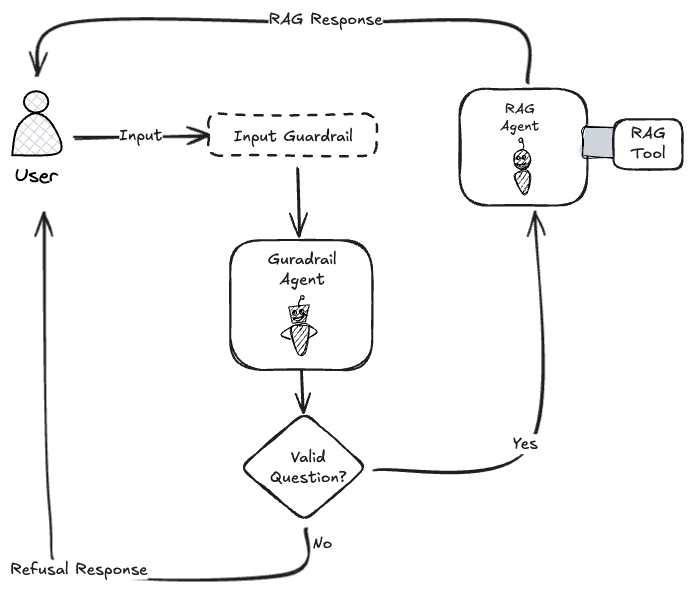
InputGuardRail
Now that we understand the intent, lets proceed with out code walkthrough.
# Initialize the LocalRAGProvider
3ollama_rag = LocalRAGProvider(model_name="nomic-embed-text:latest", chunk_size=1000, chunk_overlap=200)
ollama_rag.load_documents("./kb/")
# Define a Pydantic model for the Input Guardrail response
4class InputGuardrailResponse(BaseModel):
isValidQuestion: bool
reasoning: str
polite_decline_response: str- 3
-
Using the imported
LocalRAGProviderclass, we initialize an object usingnomic-embed-text:latestas the local embedding model and we load the KB to initialize the RAG structure. - 4
-
Then, we define a class named
InputGuardrailResponseinheriting from Pydantic’sBaseModelclass, to represent the output response we would receive from the guard rail agent. We basically want to force this guard rail agent to return its response in this class format.
This InputGuardrailResponse is NOT an SDK class. It is created for this usecase to contain 3 members :
isValidQuestion: a boolean to let us know whether or not to route the control back to the main rag agentreasoning: why did the guard rail agent think whether the input question is valid/or not?polite_decline_response: the string response which will be shown to the user, ifisValidQuestionis set tofalse
Great! so now we proceed to define the main rag agent, along with its tools.
# Define the RAG Tool
@function_tool
6def get_answer_about_pydanticai(query: str) -> str:
"""
Retrieve an answer about PydanticAI from the local RAG provider.
Args:
query (str): The question to ask.
Returns:
str: The answer to the question.
"""
print(f"[debug] Getting answer for query: {query}")
return ollama_rag.query(query)
5rag_agent = Agent(
name="RAG Agent",
instructions="You are an expert answering questions about Pydanti AI. Use the tools at your disposal to answer the question.",
model=OllamaProviderAsync().get_model(),
handoffs=[],
tools=[get_answer_about_pydanticai],
output_type=str,
)- 5
-
We create the
rag_agentas an instance ofAgentand it has access to a tool namedget_answer_about_pydanticai. - 6
-
This
get_answer_about_pydanticaiis nothing but afunction_toolthat simply callsollama_rag.queryto perform the RAG and return the response.
But, hold on where is the filter on InputGuardRail ? Don’t we need to insert this filter before this rag_agent gets the input? Where is the association?
I hear you. For sure, we need to make that association in this rag_agent’s declaration only. But before do that, we need to declare or define what InputGuardRail should be. Let us do that below.
# Define the InputGuardrail Agent
7input_guardrail_agent = Agent(
name="Input Guardrail Agent",
instructions="Check whether the input is a valid question about PydanticAI. If you determine the input is invalid, provide a polite decline response stating that you can only answer questions about PydanticAI. Don't attempt to provide answer to the question.",
model=OllamaProviderAsync().get_model(),
handoffs=[],
8 output_type=InputGuardrailResponse
)- 7
-
So first, we create the
input_guardrail_agentclass fromAgent, which will simply act as LLM as Judge to validate whether the input query is related to PydanticAI. Nothing fancy! but… - 8
-
I implore you to look this line where the
output_typeis set toInputGuardrailResponsetype. Remember we set this in Step 4. This is the way of forcing the LLM to respond in a structured format. So if we simply inspect the value ofisValidQuestion, we know whether to send a polite refusal or reroute the flow back therag_agent.
Perfect 💁🏻♂️! Now that we defined input_guardrail_agent, it is now time to associate this agent as the InputGuardRail for the rag_agent. How do we do it? Simply add it as a property. See below!
# Define the InputGuardrail function
9async def pydanticai_input_guardrail(ctx, agent,input_text):
result = await Runner.run(input_guardrail_agent, input_text)
10 final_result = result.final_output_as(InputGuardrailResponse)
return GuardrailFunctionOutput(
output_info=result,
11 tripwire_triggered= not final_result.isValidQuestion,
)
# Define the RAG Agent
rag_agent = Agent(
name="RAG Agent",
instructions="You are an expert answering questions about Pydanti AI. Use the tools at your disposal to answer the question.",
model=OllamaProviderAsync().get_model(),
handoffs=[],
tools=[get_answer_about_pydanticai],
output_type=str,
12 input_guardrails=[
InputGuardrail(guardrail_function=pydanticai_input_guardrail)
]
)- 9
-
We first wrap calling this
input_guardrail_agentagent inside anasyncfunction namedpydanticai_input_guardrail. - 10
-
Within this function, we cast the
RunResultof the agent toInputGuardrailResponseand return an instance ofGuardrailFunctionOutput. - 11
-
The definition of
GuardrailFunctionOutputclass contains 2 key properties.output_infowhich is the refusal output from the guard rail agent andtripwire_triggeredproperty which is set to thenot final_result.isValidQuestion. - 12
-
We then finally associate this
pydanticai_input_guardrailas theguardrail_functionhook of therag_agentby setting theinput_guardrailsproperty to anInputGuardrailinstance.
Okay! so that’s it right? We made the necessary definitions and hooks and we can just fire the Runner.run() on the rag_agent like below right?
async def main():
result = await Runner.run(rag_agent, "How do I install pytorch?")
print(f"Result: {result.final_output}")Well not quite!!
The real deal of tripwire_triggered
Well you see, this tripwire_triggered is actually to throw an exception, specifically InputGuardrailTripwireTriggered exception!
What this means is, if the GuardRail triggers this trip wire i.e if the input_guardrail_agent sets the isValidQuestion as false, then this trip wire is triggered and it will throw an InputGuardrailTripwireTriggered exception.
Caution
What is not documented clearly or shown in the OpenAI SDK documentation is that, the usage of InputGuardRail or OutputGuardRail involves exception handling from the coding logic. It doesn’t behave like a handoff where, the next agent is marked as the GuardRail agent if the guard rail condition is met.
I’m NOT saying this is a bad practice, but it certainly didn’t meet my expectation that I had5. So in reality, the application developer should handle this exception to either halt the execution or take other mitigation as necessary for the usecase. In this example, we are simply going to use the polite_decline_response property of the output to send the refusal response to the user.
async def main():
try:
result = await Runner.run(rag_agent, "How do I install pytorch?")
print(f"Result: {result.final_output}")
13 except InputGuardrailTripwireTriggered as e:
print(f"[debug] Tripwire triggered: {e.guardrail_result.
output.
output_info.
final_output.
14 polite_decline_response}")
if __name__ == "__main__":
asyncio.run(main())- 13
-
We simply catch the
InputGuardrailTripwireTriggeredexception and.. - 14
-
Use the
guardrail_resultas we see fit.
The full end to end example is hosted in openai-local-agents repo.
Too much abstraction!
So, we went over an example of using Input Guardrails. The same pattern can be extended to OutputGuardRail as well. Instead of filter the input to the agent, we will be filtering the output from the agent, that’s the difference.
What could have been a simple callback hooks, is pretty convoluted in my opinion. If we take a step back and zoom out, this is what is happening Figure 2.
The main agent rag_agent is setup with a InputGuardRail object which is nothing but wraps a guardrail_function function to call back during the input hook trigger. This function throws an instance of GuardrailFunctionOutput. If this GuardrailFunctionOutput object’s tripwire_triggered property is set, InputGuardrailTripwireTriggered exception is thrown. This exception is then used to decide the next course of action.
A simple callback is implemented as convoluted 7 steps.
This is what I term as bloated in the beginning. And not only that, these guard rails can also be chained together, based on the spec that input_guardrails is a list. So multiple input guard rail(s) clubbed with multiple output guard rail(s) will definitely eat up more resources and make it much more difficult to debug and maintain in the long run.
It is no wonder, OpenAI advertises its tracing system, along side their agents sdk!
And look at how many objects we need to cross to get to the polite_decline_response !!! 🤪🤪😆
Wrap up!
Before I wrap up, I do wanna caution you that much of this guardrails depend on the implementation of guardrail_function (in our case it was pydanticai_input_guardrail). If you resort to LLM as Judge implementation, like what we did in our example, the trigger to either pivot or reroute to the main agent, solely depends on the LLM Judge’s performance.
When I tried experimenting this code, 8/10 times the LLM judge model failed to provide proper output in the expected format. Obviously, the OpenAI agents SDK is not the culprit, but the underlying model is. Since I’m using a severely quantized model compared to other frontier models, this is a known limitation. But hey! its free!
So don’t fret too much if you aren’t able to reproduce this experiment in one go. Try multiple times with multiple models and choose the one that is reliable.
This concludes Part 3 of my journey. If you are with me so far, then you will definitely enjoy the final part of this series, where I plan to cover Contexts, MCP and Parallel agents.
See you soon! à bientôt!
Subscribe to Techno Adventure Newsletter
I also publish a newsletter where I share my techo adventures in the intersection of Telecom, AI/ML, SW Engineering and Distributed systems. If you like getting my post delivered directly to your inbox whenever I publish, then consider subscribing to my substack.
I pinky promise 🤙🏻 . I won’t sell your emails!
Footnotes
Unique Selling Point↩︎
It could also be the same model that gets used under the hood, both the judge and the candidate LLM won’t share context.↩︎
I just wanted to sound scientific, but the entire input along with context and agent is passed to this filter.↩︎
I understand LLM as Judge terminology is used when the input to be validated is a LLM output. But I’m using it here in a broader sense wherein I use LLM not to answer the actual user query, but to decide whether or not to answer.↩︎
based on the handoff pattern.↩︎