What’s 🥣 cooking in 🦙 LLMs for 📡 Telecom?

Yes you guessed it right. Figure 1 is an AI generated image. But then isn’t it normal nowadays? Everything, starting from your mobile to next neighbor’s washing machine or dishwasher, is powered by AI.
So then why not telecom? Eh! . That’s how I started to approach this topic. But as I delved deep in to this, it became interesting.
How it all began?
Well the concept or premise of intelligent network is not something new. It existed even when I was studying my high-school. Although the degree of intelligence was constantly evolving. But as GPU started powering the media machine of this artificial intelligence, slowly & steadily almost every industry went after this next shiny object. But AI/ML was not “this” shiny then until Mr sama unveiled Chat-GPT. So before that act of unveilment, following are the telecom specific intelligent use-cases that I was aware of :
- Chatbots for customer support
- This included anything and everything goes from orders, delivery, billing, tech support etc. You know those chat bots that ask for too much personal info and provide a canned response to end where you will get frustrated and type
chat with humankinda of the bot 🤖.
- This included anything and everything goes from orders, delivery, billing, tech support etc. You know those chat bots that ask for too much personal info and provide a canned response to end where you will get frustrated and type
- Pseudo intelligent Network Automation / Operations - The reason I call them as pseudo is because of the fact that none of these methods included adhoc (aka zero shot learning) and almost all of them are some rules based.
- Closed loop service assurance based on events, alarms
- This was the most hyped usecase touting intelligence and included a flair of ML using traditional statistical models.
- Closed loop service assurance based on events, alarms
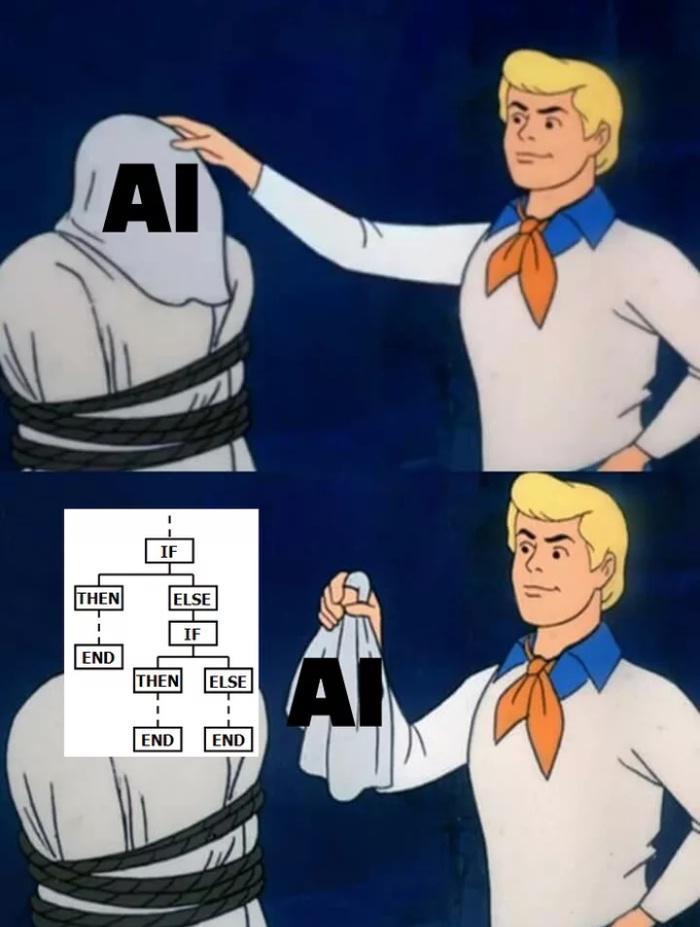
Ofcourse these chatbots were like today’s Siri & Alexa (wake up Apple & Amazon) which were useful and works like a charm for demos but seldom added meaningful values in real world. It was a glorified “if-then-else” loop with bunch of rules to pick from, but wrapped inside the “intelligence” jargon.
After Chat-GPT made the GPT popular, LLMs are now everywhere. Figure 2 shows apt memes I guess!

Before we delve into further, lets try to understand what is a LLM?
LLM - The Basics
Okay time for a quick crash course if you are totally new to LLMs. Otherwise feel free to skip this section.
LLMs aka Large Language Models can be understood as a database of numbers that a machine can interpret. This database of numbers will be created by some company or companies by training the machine to interpret real-world data as a set of numbers.
Basically you convert a data for eg a text or an audio or a picture into series of numbers and then you assign a label to that series of number. This label is again a human readable data, hence even this label will be converted into a number and then stored along with the database. Hence for this machine, both the input and the output are nothing but a series of numbers as represented in Figure 3
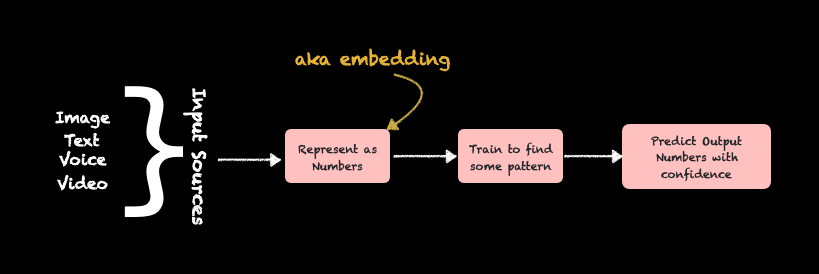
The process of converting an input to a series of numbers is called as Embedding. The output of training will contain this series of numbers which is called as weights & biases. This is what constitute as a machine learning model. Now if this model is predominantly trained on natural language 1 (such as spoken languages) it becomes a Language Model. . Again, if the sheer size of that resultant model is so huge such that it contains millions and billions of numbers, weighing multiple GBs of data, it then becomes a Large Language Model.
- Language Model (LM) == A database of numbers representing some knowledge / information
- Large Language Model (LLM) == A LM that spans billions in size.
Evolution story of LLMs
Now lets look at the evolution story of LLMs. Within traditional ML world, a Neural Network represents the concept of intelligent function \(f(y)\) that is capable of taking an input number (refer \(x\) in Equation 1) and produce the output number (refer \(y\) in Equation 1) based on what it learns (refer \(W\) and \(b\) in Equation 1) from the inputs.
This intelligent function \(f(y)\) can be optimized to improve its accuracy by teaching this function reduce the loss (refer \(C\) in Equation 2) between expected output \(y\) and the produced output number \(\hat y\) .
\[ f(y) = W.x + b \tag{1}\]
\[ C = 1/n \sum_{i=1}^{n} (y_i - \hat y_i)^2 \tag{2}\]
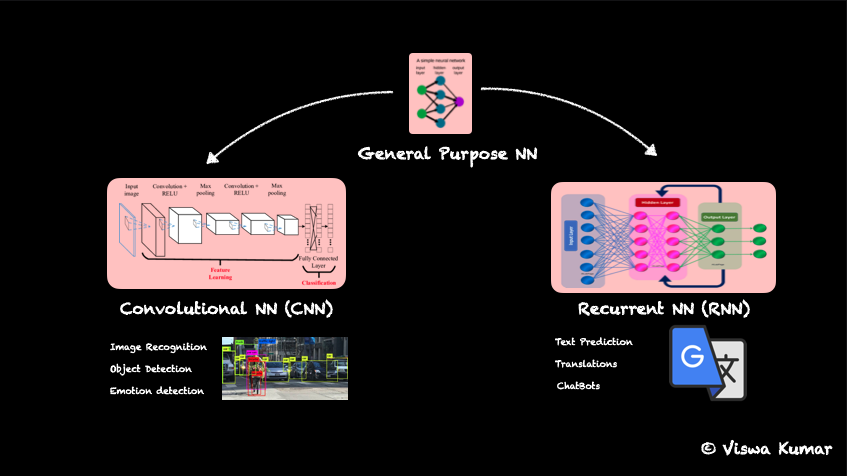
What started as a modest number predicting function, slowly but steadily grew to predict text and image data which gave birth to fine tune NNs such as CNNs and RNNs.
Phase 1 of LLMs - Sophisticated NNs, Transformers, GPTs
Convolutional NN (CNN) was used in image processing tasks such as object recognition, face detection, emotion detection etc, where as Recurrent NN (RNN) got specialized into text processing tasks such as next word prediction, translations, primitive chat agents etc. Figure 4 (a)
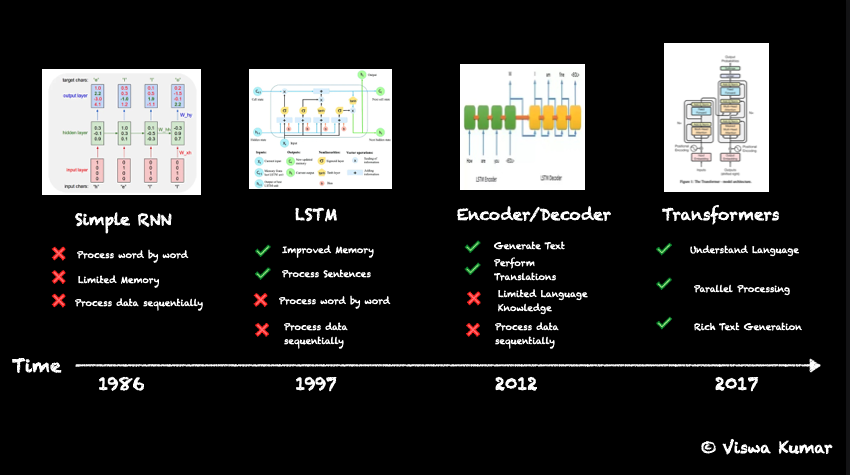
First generation of RNNs (aka Simple RNNs) was introduced around 1986 (yeah this concept is that old) and had lot of limitations such as word-by-word processing, less memory, and also processed data sequentially. This means they have no context and very easily forget what it learnt and there by less useful. This gave birth to LSTM (Long Short-Term Memory) models, introduced in 1997, where the memory got improved but it still processed sequentially. This means, it couldn’t be scaled well. Then in 2012, Encoder/Decoder models was proposed. This had 2 separate systems, one to take input number and produce the knowledge and one to predict the output number from the gained knowledge. This opened up lot of opportunities, but yes… you guessed it, still processed data sequentially. Here is where Google put on a superman suite and published Transformer paper with the famous “Attention is all you need” title in 2017. This opened the pandora’s box which paved the basement for GPTs. Figure 4 (b)
Right at the same time, GPUs entered the scene and poured the much needed midnight oil. This along with the transformer model put the innovation in steroids. OpenAI was formed in 2015, but published their first GPT model in 2018. It was called GPT aka Generative Pre-trained Transformer model. This was an early version of LLM, since the training data consisted of ~120M parameters. Around similar time, Google also introduced a fundamental model called BeRT containing 240M parameters. The innovation was so rapid where OpenAI rapidly published GPT-2 with 1.5B and GPT-3 with 175B parameters. This GPT-3.5 is what made headlines as chat-GPT in Nov 2022. And as they say, rest is the history Figure 4 (c)
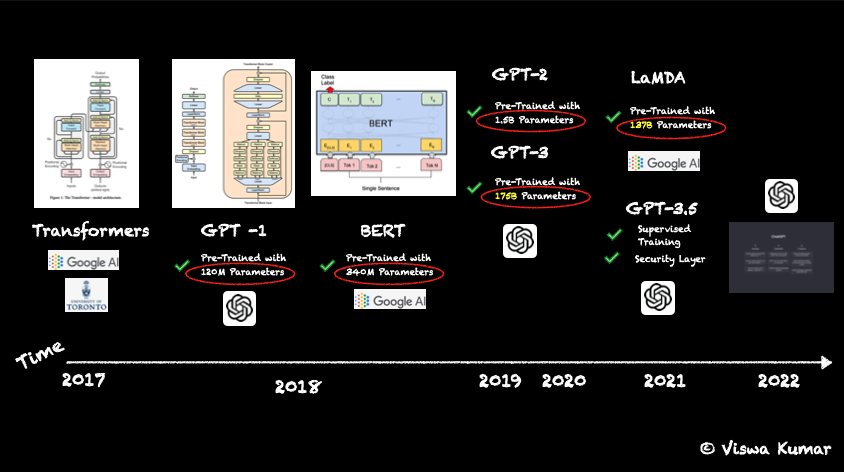
Phase 2 of LLMs - Post Chat-GPT
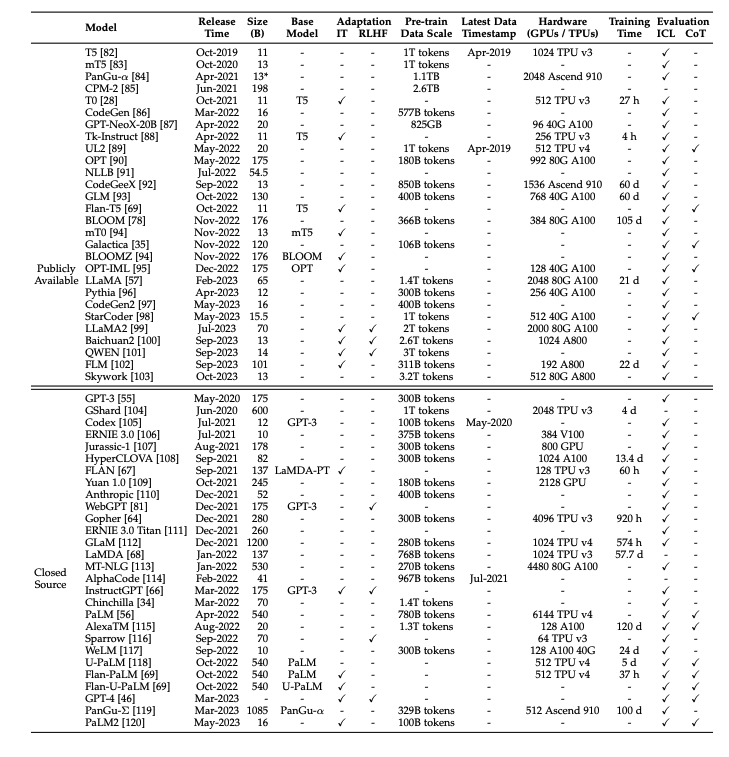
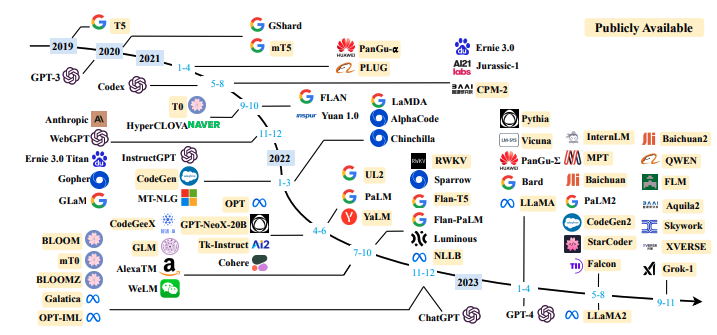
Post Chat-GPT disruption, almost every research institute and academic institutions pushed their 5th gear into AI/ML. As per the paper published by Wayne Xin Zhao et All [1], around 56 LLMS (including open & closed sources) with ground breaking research got published. This is what I call as Phase 2 of the LLMs Figure 5
Potential Usecases of LLMs for Telecom
Having learnt the history of LLMs, let us now try to see what’s in it for Telecom. Based on what I see both in industry and academia, following are the potential paths LLMs may take in ruling the telecom industry
- Customer Service & Network Operation & Automation
- These 2 are more of an extended, fine-tuned, perhaps most immediate usecases that I see getting crystallized. However this is no way a telecom specific usecase. It is as good as applicable for any industry, any enterprise for that matter.
- Network Planning & Design with Visual, Spatial prediction
- This something new and I see active research happening as we speak. The basic idea is help design the network, especially in site survey etc using AI’s prediction. The idea is to feed spatial, geographical & even site images thereby the model can predict the placement of antennas, its direction etc to maximize throughput
- There is a growing number of research happening on RIS (Reconfigurable Intelligent Surfaces) . Here is a repo that contains growing number of research papers in this topic. More on RIS on my upcoming blogs.
- Network implementation & standardization from specification through code generation
- Another interesting research path that I stumbled upon is using AI to either influence or even create a telecom system using GPT’s code generation capability. VS Copilot and other Code / Instruct GPT models are capable of generating working code based on input instructions. In this research path, this capability could be used to implement a telecom system like network function, interfaces by feeding in a 3GPP / ETSI specification or even compare and contrast vendor implementations to arrive a reference point. This will become a boon for service providers (if materialized) to solve the system-integration nightmares as they call it.
- Ofcourse several standard bodies like ORAN, 3GPP are already publishing guidance, reference implementations of using AI driven apps to predict something, be it a configuration change, deployment specific change or even infrastructure decisions like placement, scaling, scheduling, life-cycle-management decisions etc in standardized / uniform way. Although this is a step in right direction and very encouraging to see, I would still categorize them as an improvement to pseudo-intelligence which I explained at the beginning of my blog.
Well, if you are at this point, then please accept my sincere thanks for your patience and really appreciate for giving me your time. I hope it was worth it. I intend to blog more on the intersection of telecom, wireless research, artificial intelligence and if that is something that resonates with you, please do follow my blog.
I also publish a newsletter where I share my techo adventures in the intersection of Telecom, AI/ML, SW Engineering and Distributed systems. If you like getting my post delivered directly to your inbox whenever I publish, then consider subscribing to my substack.
I pinky promise 🤙🏻 . I won’t sell your emails!